One of our clients with a large international user base asked us to help them with reporting on the different languages people were using on the site. Google Analytics collects data on a user’s language setting, and reports on it by a set of language codes that not reader-friendly. There are also several dialects listed for some more widely used languages, like English and Spanish. Our client did not need this level of detail in this report. Essentially, they needed a simple chart with the full name of the language used and how many sessions (users, events, etc.) used that language.
I thought this would be an easy task because I assumed that either a) Google would have some built-in setting to do this or b) someone would have posted a simple copy/paste formula for converting language codes to language names. I assumed wrong, and it ended up taking some time. Now I’m posting the formula I used here for others to copy/paste away. Write the blog post you want to see the world, I suppose.
Here’s how to convert Google language codes from Google Analytics to full language names in Google Data Studio.
This solution uses a CASE formula to create a custom field that combines like languages and outputs full language names instead of language codes.
Step 1: Add a custom field.
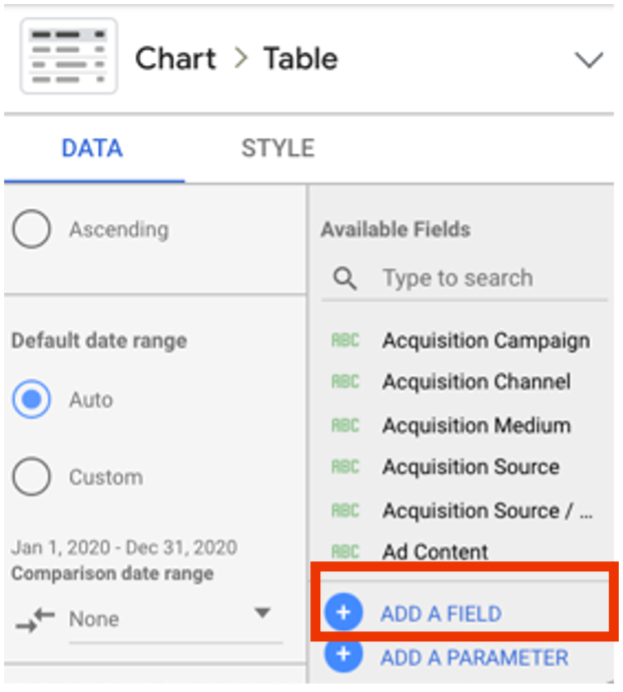
Step 2: Name the custom field something other than Language (to avoid duplicate field names).
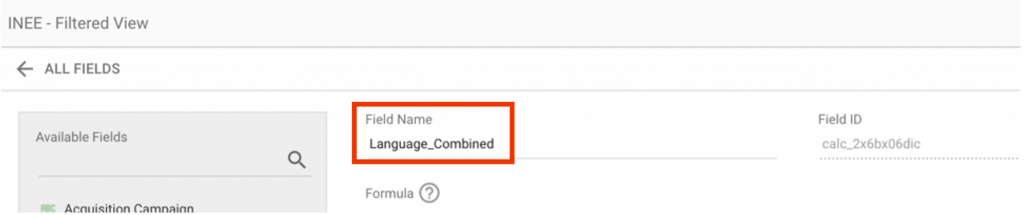
Step 3: Copy and paste the formula at the end of this post into the formula area. Make sure to include the whole formula through the word “END.”
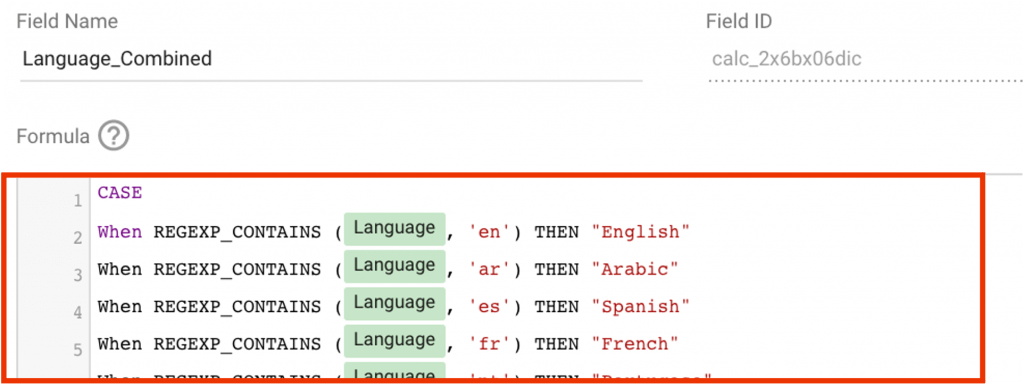
This formula tells Data Studio to look for data in the Language field—which is pulled in from Google Analytics—that matches the parameter we defined using Google’s language codes. WHEN it finds it, THEN it follows the direction we give it for how to display it, which is the full language name.
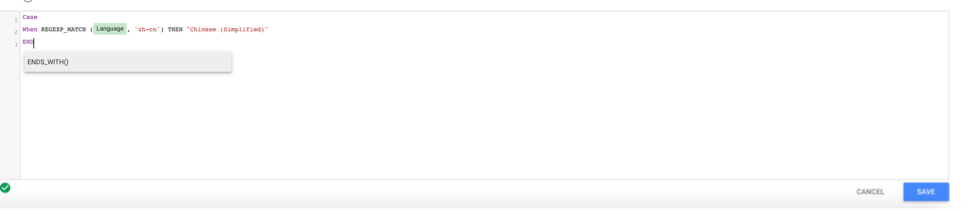
This formula uses REGEXP_CONTAINS to find data that contains the values we are looking for. If you want to find only exact matches, use REGEXP_MATCH. I did this for the three variations of Chinese because they are different languages that all start with zh:
- When REGEXP_MATCH (Language, ‘zh-cn’) THEN “Chinese (Simplified)”
- When REGEXP_MATCH (Language, ‘zh-tw’) THEN “Chinese (Traditional)”
- When REGEXP_MATCH (Language, ‘zh-hk’) THEN “Chinese (Hong Kong)”
Step 4: Save your custom field.
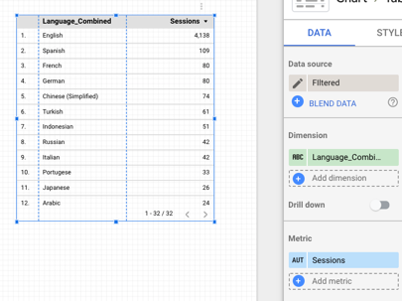
 Step 5: Start using your new custom field to create charts. You’ll now find it listed as an available dimension. Here’s how it looks in a table with new users as the metric.
Step 5: Start using your new custom field to create charts. You’ll now find it listed as an available dimension. Here’s how it looks in a table with new users as the metric.
Language Custom Field Formula
CASE
When REGEXP_CONTAINS (Language, ‘en’) THEN “English”
When REGEXP_CONTAINS (Language, ‘ar’) THEN “Arabic”
When REGEXP_CONTAINS (Language, ‘es’) THEN “Spanish”
When REGEXP_CONTAINS (Language, ‘fr’) THEN “French”
When REGEXP_CONTAINS (Language, ‘pt’) THEN “Portugese”
When REGEXP_CONTAINS (Language, ‘am’) THEN “Amharic”
When REGEXP_CONTAINS (Language, ‘it’) THEN “Italian”
When REGEXP_MATCH (Language, ‘zh-cn’) THEN “Chinese (Simplified)”
When REGEXP_MATCH (Language, ‘zh-tw’) THEN “Chinese (Traditional)”
When REGEXP_MATCH (Language, ‘zh-hk’) THEN “Chinese (Hong Kong)”
When REGEXP_CONTAINS (Language, ‘de’) THEN “German”
When REGEXP_CONTAINS (Language, ‘nl’) THEN “Dutch”
When REGEXP_CONTAINS (Language, ‘tr’) THEN “Turkish”
When REGEXP_CONTAINS (Language, ‘ja’) THEN “Japanese”
When REGEXP_CONTAINS (Language, ‘da’) THEN “Danish”
When REGEXP_CONTAINS (Language, ‘af’) THEN “Afrikaans”
When REGEXP_CONTAINS (Language, ‘hy’) THEN “Armenian”
When REGEXP_CONTAINS (Language, ‘az’) THEN “Azerbaijani”
When REGEXP_CONTAINS (Language, ‘eu’) THEN “Basque”
When REGEXP_CONTAINS (Language, ‘bn’) THEN “Bengali”
When REGEXP_CONTAINS (Language, ‘ca’) THEN “Catalan”
When REGEXP_CONTAINS (Language, ‘hr’) THEN “Croatian”
When REGEXP_CONTAINS (Language, ‘cs’) THEN “Czech”
When REGEXP_CONTAINS (Language, ‘et’) THEN “Estonian”
When REGEXP_CONTAINS (Language, ‘fil’) THEN “Filipino”
When REGEXP_CONTAINS (Language, ‘fi’) THEN “Finnish”
When REGEXP_CONTAINS (Language, ‘gl’) THEN “Galician”
When REGEXP_CONTAINS (Language, ‘ka’) THEN “Georgian”
When REGEXP_CONTAINS (Language, ‘el’) THEN “Greek”
When REGEXP_CONTAINS (Language, ‘gu’) THEN “Gujarati”
When REGEXP_CONTAINS (Language, ‘iw’) THEN “Hebrew”
When REGEXP_CONTAINS (Language, ‘hi’) THEN “Hindi”
When REGEXP_CONTAINS (Language, ‘hu’) THEN “Hungarian”
When REGEXP_CONTAINS (Language, ‘is’) THEN “Icelandic”
When REGEXP_CONTAINS (Language, ‘id’) THEN “Indonesian”
When REGEXP_CONTAINS (Language, ‘kn’) THEN “Kannada”
When REGEXP_CONTAINS (Language, ‘ko’) THEN “Korean”
When REGEXP_CONTAINS (Language, ‘lo’) THEN “Laothian”
When REGEXP_CONTAINS (Language, ‘lv’) THEN “Latvian”
When REGEXP_CONTAINS (Language, ‘ms’) THEN “Malay”
When REGEXP_CONTAINS (Language, ‘ml’) THEN “Malayalam”
When REGEXP_CONTAINS (Language, ‘mr’) THEN “Marathi”
When REGEXP_CONTAINS (Language, ‘mn’) THEN “Mongolian”
When REGEXP_CONTAINS (Language, ‘no’) THEN “Norwegian”
When REGEXP_CONTAINS (Language, ‘fa’) THEN “Persian”
When REGEXP_CONTAINS (Language, ‘pl’) THEN “Polish”
When REGEXP_CONTAINS (Language, ‘ro’) THEN “Romanian”
When REGEXP_CONTAINS (Language, ‘ru’) THEN “Russian”
When REGEXP_CONTAINS (Language, ‘sr’) THEN “Serbian”
When REGEXP_CONTAINS (Language, ‘si’) THEN “Sinhalese”
When REGEXP_CONTAINS (Language, ‘sw’) THEN “Swahili”
When REGEXP_CONTAINS (Language, ‘sv’) THEN “Swedish”
When REGEXP_CONTAINS (Language, ‘ta’) THEN “Tamil”
When REGEXP_CONTAINS (Language, ‘te’) THEN “Telugu”
When REGEXP_CONTAINS (Language, ‘th’) THEN “Thai”
When REGEXP_CONTAINS (Language, ‘uk’) THEN “Ukrainian”
When REGEXP_CONTAINS (Language, ‘ur’) THEN “Urdu”
When REGEXP_CONTAINS (Language, ‘vi’) THEN “Vietnamese”
When REGEXP_CONTAINS (Language, ‘zu’) THEN “Zulu”
Else “Other”
END
